핀테크 개발자가 본 KakaoTalk 온디바이스 AI의 의미

지난 글에서 카카오의 Kanana-o 멀티모달 모델로
음성 의사결정 앱 “아무거나(amuguna)”를 만든 경험을 정리했다.
그 글은 모델을 코드에 녹이는 입장의 분석이었다.
이번 글은 카카오가 같은 Kanana 모델 가족 중 다른 한 갈래를
일반 사용자 톡 안에 넣은 결과를 켜본 후기다.
Kanana in KakaoTalk.
평소 핀테크 도메인에서 LLM을 다루는 입장에서 이번 출시는 세 가지 지점이 흥미로웠다.
대화 컨텍스트를 메모리에 들고 가는 동작,
한국 컨텍스트를 알아서 챙기는 동작,
온디바이스 모델로 톡 대화가 외부로 나가지 않는다는 설계 결정이다.
세 가지를 차례로 풀어본다.
한강 피크닉 한 번 가려고 켜봤다
날이 좋아 친구 5명이서 한강 피크닉을 가기로 했다.
누구는 매운 걸 못 먹고 누구는 면 요리를 싫어한다.
어떤 걸 배달시켜 먹을까 하다가 최근에 베타에 들어온 Kanana in KakaoTalk이 생각났다.
그래서 카톡에서 한 번 켰다.
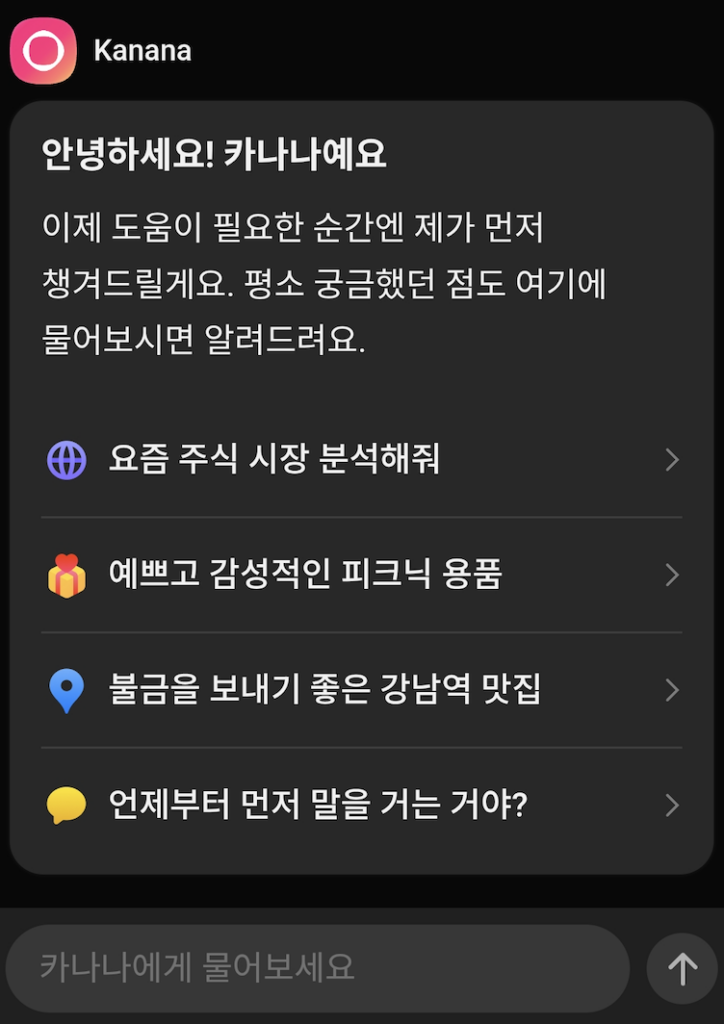
처음엔 단순히 “한강 맛집”을 물어봤다
1. 누적 대화 컨텍스트를 메모리에 들고 재랭킹한다
“한강 피크닉 갈건데 맛집 알려줘”로 5곳을 받았다.
이어서 “친구가 매운 걸 못 먹어, 면도 싫어해”라고 덧붙였다.
그러자 모델이 새로 검색하지 않고 직전 5곳 중에서 친구 조건에 맞는 3곳을 다시 골라냈다.
새 검색 호출이 아니라 직전 후보군을 메모리에 들고 있는 상태에서 새 조건을 입혀 필터링한 동작이다.
Kanana-o로 의사결정 앱을 만들면서 가장 신경 쓴 부분이 이 누적 컨텍스트 관리였다.
음성·이미지·텍스트가 한 번에 들어오는 옴니모달이라도,
클라이언트에서 직전 턴의 추천 후보를 들고 있지 않으면
“그것 중에서 다시”라는 사용자 후속 요청을 처리할 수 없다.
amuguna에서는 이걸 클라이언트 메모리에 후보 목록을 들고 있다가
다음 호출의 시스템 프롬프트에 끼워 넣는 방식으로 풀었다.
Kanana in KakaoTalk은 이걸 사용자가 의식할 필요 없이 자연스럽게 처리한다.
단순 추천 API로는 이 동작이 안 나온다.
각 호출이 독립적인 검색이라면 두 번째 사용자 입력에서
“직전 5곳 중에서”라는 기준점이 사라지기 때문이다.
대화 메모리에 후보군을 유지하면서 새 조건을 입혀 재랭킹하는 동작은
LLM 비서가 “검색기”가 아니라 “비서”로 동작하기 위한 최소 조건이다.

2. 한국 컨텍스트를 알아서 챙긴다
“이제 한강에서 배달 시켜먹을거야”라고만 추가로 입력했다.
그러자 모델이 묻지도 않은 정보를 알아서 꺼냈다.
- 한강공원 전역이 2025년부터 제로 플라스틱존으로 지정되어 일회용 배달 용기 사용이 제한된다는 점
- 배달의민족·쿠팡이츠·요기요에서 다회용기 카테고리를 선택해야 한다는 점
- 여의도·뚝섬·반포 등 주요 한강공원에는 지정된 배달존이 있고 주문 시 상세 주소에 그 번호를 기입해야 한다는 점
같은 질문을 글로벌 LLM에 했다면 “한강에서 배달 서비스를 이용할 수 있다” 정도의
일반론적인 답이 돌아왔을 가능성이 높다.
한강공원 제로 플라스틱존이라는 정책 자체가 학습 데이터에 충분히 들어가 있지 않을 가능성도 크다.
한국 사용자에게 보이는 디테일을 모델이 알아서 챙긴다는 게 이번 글의 본질적 차별점이다.
“한국어를 잘함”이 아니라 “한국 사용자가 한국 상황에서 부딪히는 컨텍스트를 알아서 처리해줌”이다.
이 차이는 모델 벤치마크 점수로는 잘 안 잡힌다.
영어 MMLU 점수가 똑같이 80이어도
한국 사용자가 한국에서 부딪히는 실제 시나리오에서의 유용성은 차이가 크다.

3. 온디바이스 모델 — 톡 대화가 외부로 나가지 않는다
Kanana in KakaoTalk의 첫 화면이 이렇게 설명한다.
“AI 모델은 기기 안에서 동작해요. 카카오톡 대화를 전송하거나 저장하지 않아요.”
Kanana Nano 온디바이스 모델이 휴대폰 안에서만 돌아간다는 의미다.
톡 대화 원문이 카카오 서버로 전송되지 않고, 모델은 휴대폰 안에서 추론을 수행한다.
핀테크 도메인에서 일하는 입장에서 이 부분이 가장 인상적이었다.
핀테크에서 클라우드 LLM을 쓰기 주저하는 이유가 정확히 이 지점이다.
거래 데이터, 고객 PII, 통신 내역 등이 외부 LLM 제공자의 인프라로 흘러나가는 게
규제·감사·정보보안 측면에서 자주 막힌다.
그래서 핀테크에서는 사내 모델을 자체 호스팅하거나,
Azure OpenAI처럼 데이터 잔류 보장이 있는 옵션을 쓰거나, 민감 필드를 마스킹한 뒤 호출하거나 한다.
카카오가 일반 사용자 톡에서 이 표준을 가져왔다는 건 두 가지 의미가 있다.
첫째, 톡 대화는 본질적으로 민감 데이터다.
가족·친구·동료와의 사적 대화에 거래 내역·약속·문서 공유까지 다 톡에서 일어난다.
이 데이터를 외부로 안 보낸다는 선택은 일반 사용자 입장에서도 본질적으로 옳다.
둘째, 핀테크에서 별도 솔루션을 큰 비용 들여 구축해야 가능했던 보안 표준이
일반 사용자 톡에서 기본값으로 제공된다.
Kanana Nano 2.1B는 어떻게 설계됐나
카카오 공식 자료를 보면 Kanana Nano는 다음과 같은 설계 결정으로 만들어졌다.
- 한국어 토크나이저 재설계: 토크나이저를 완전히 갈아엎어 한국어 토큰 처리 효율을 30% 개선했다. 같은 한국어 문장을 토큰화했을 때 토큰 수가 30% 적다는 의미고, 이건 그대로 추론 속도와 메모리 절감으로 이어진다.
- MLA(Multi-head Latent Attention) 채택: 표준 트랜스포머의 multi-head attention 대신 latent 공간에서 압축한 형태의 attention을 쓴다. KV 캐시 크기가 크게 줄어들어 모바일 환경에서 메모리 효율이 좋아진다.
- 학습 비용 50% 절감: 비슷한 크기의 다른 모델 대비 학습 최적화로 50% 이상 비용을 줄였다. 카카오 테크니컬 리포트에 수치가 공개되어 있다.
- Kanana Safeguard 오픈소스 공개: AI 가드레일 모델을 국내 최초로 오픈소스로 풀었다. 사내에서만 쓸 법한 안전성 검증 모델을 공개했다는 건 카카오 AI 생태계 자체를 키우려는 신호로 읽힌다.
Privacy First 원칙은 위의 설계 결정들과 일관된다.
모델을 충분히 가볍게 만들어서 온디바이스에서 돌릴 수 있게 하고,
그 결과 사용자 대화 원문이 외부로 나갈 필요 자체를 없앤다.
벤치마크 점수를 올리는 방향과는 다른 종류의 엔지니어링 결정이고,
이 방향이 실제로 일반 사용자 톡에서 실현됐다는 게 흥미로운 지점이다.
핀테크 관점에서 본 의미
amuguna를 만들 때는 BYO-key + 라우팅 가드로 보안을 풀었다.
사용자가 본인 Kanana-o API 키를 입력해야 동작하고,
키가 없으면 라우팅 가드가 설정 화면으로 강제 이동시킨다.
OSS로 코드를 공개하면서 공용 데모를 일부러 안 만든 이유도 비슷하다.
키와 호출 비용의 책임은 사용자에게 있고 운영 측 비용은 0이며 키 노출도 0이다.
이 설계가 안전한 이유는 “모델 호출 비용과 데이터 흐름을 사용자가 통제한다”는 점이다.
Kanana in KakaoTalk은 다른 방향으로 같은 문제를 푼다.
모델을 온디바이스로 옮겨서 데이터 흐름을 아예 차단한다.
비용은 카카오가 부담하고, 데이터는 휴대폰을 안 떠난다.
이 차이가 핀테크 도메인에서도 비슷한 갈림길로 보인다.
내부 LLM 워크플로우에서 민감 데이터를 다룰 때 두 가지 길이 있다.
첫째, 클라우드 LLM을 쓰되 PII 마스킹·암호화·잔류 보장으로 풀기.
둘째, 온디바이스 또는 사내 호스팅 경량 모델로 데이터를 아예 안 보내기.
지금까지는 두 번째 길이 운영 부담 때문에 잘 안 쓰였다.
카카오가 일반 사용자 톡에서 두 번째 길을 기본값으로 가져왔다는 건
핀테크에서도 비슷한 라이트한 워크로드(예: 거래 메모 분류, 알림 요약 같은)는
온디바이스 경량 모델로 옮길 수 있다는 신호다.
물론 핀테크 분류기는 4-5천 토큰의 시스템 프롬프트가 필요한 경우가 많아서
2.1B 클래스 온디바이스 모델로 그대로 옮기는 건 어렵다.
다만 사용자가 휴대폰에서 직접 처리하는 라이트한
LLM 워크로드(앱 내 짧은 요약, 입력 보조 같은)는 충분히 검토해볼 만하다.
마치며
Kanana in KakaoTalk이 보여준 세 가지 동작은 결국 한 가지 메시지로 정리된다.
일상에 스며드는 AI는 “검색기”가 아니라 “비서”여야 하고
그러려면 컨텍스트를 들고 가고
사용자의 도메인을 알고 데이터를 외부로 안 보내야 한다.
이 세 조건을 일반 사용자 톡에서 기본값으로 제공한다는 게 이번 출시의 본질이다.
다음 글에서는 카카오가 같이 풀어내고 있는
AI국민비서, Kakao Tools처럼 같은 방향의 다른 갈래들도 차례로 켜본다.
