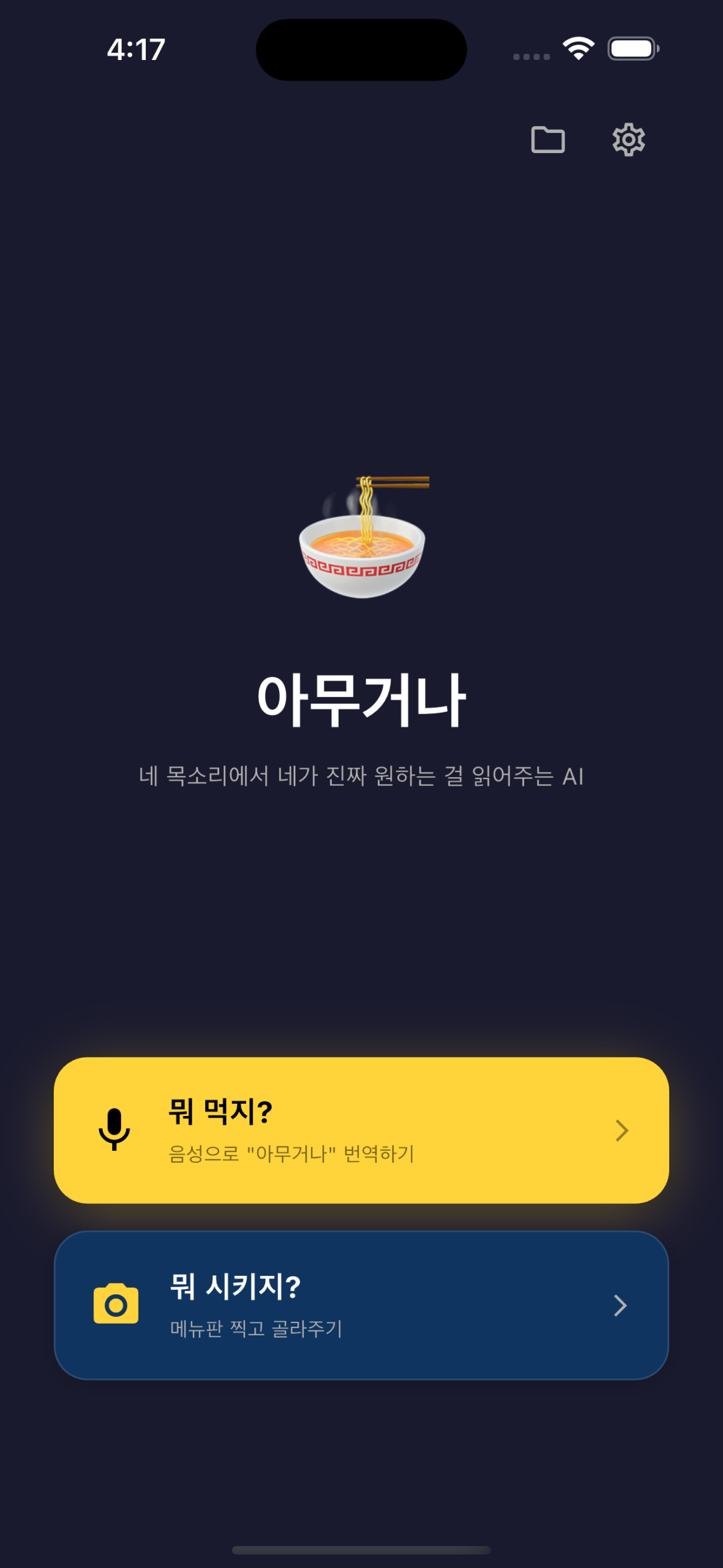
카카오 AI 앰배서더로 활동하며 한 달 가까이 Kanana-o를 사용해 직접 코드에 녹여봤다.
결과물은 음성 감정 분석 기반 의사결정 도우미 앱 “아무거나(amuguna)”이다.
GitHub: github.com/PlutoJoshua/amuguna
Kanana-o 베타 테스터 후기 글들을 찾아 읽어보면 명함 분석, 채용 챗봇, 음성 페르소나 같은 사례는 많은데
실제 모바일 네이티브 앱에 연동한 사례는 드물다.
한 달동안 Flutter 앱에 직접 연동하면서 검증한 강점과
비결정적 멀티모달 모델을 클라이언트에서 다루는 패턴을 정리한다.
글은 두 부분으로 나뉜다. 1부는 Kanana-o의 강점이 코드 한 줄 한 줄에 어떻게 영향을 줬는지 검증한 결과다.
2부는 이 검증 과정에서 부딪힌 비결정성을 클라이언트에서 어떻게 우회했는지의 패턴이다.
1부 — 검증된 Kanana-o 강점 3가지
1-1. DPO 감정 미러링: 분기 코드 100줄이 사라진다
가장 인상 깊었던 부분이다.
사용자 음성이 피곤하면 응답 음성도 부드럽게 나온다. 코드로 제어하지 않는다.
DPO(Direct Preference Optimization) 학습 효과로 모델이 알아서 감정 미러링을 한다.
처음엔 “음성 감정 분석 → 분류 → 톤 분기 → 응답 생성” 100줄짜리 로직을 짜려 했다.
막상 시스템 프롬프트 4줄만 넣어보니 모델이 알아서 했다.
5. 감정/의도 이해는 본문에 자연스럽게 녹여라.
예) "지금 좀 지쳐 보이는데, 따뜻한 칼국수 어때요?"
예) "오, 들떠있네! 매콤한 거 한 번 도전해볼래?"
(lib/features/chat/data/prompts/mode_a_prompt.dart)
GPT-4o로 같은 프롬프트를 넣었을 때 응답 텍스트는 비슷했지만 음성 톤은 평이했다.
DPO의 진짜 가치는 텍스트가 아닌 음성 응답에서 드러난다.
1-2. 옴니모달 단일 모델: 모달 간 컨텍스트가 사라지지 않는다
“아무거나”는 두 모드를 가진다.
- 모드 A: 음성 대화로 메뉴 좁히기
- 모드 B: 메뉴판 사진 + 그 안에서 음성 대화
같은 옴니모달 모델이 음성·이미지·텍스트를 다 처리하니
모드 A에서 파악한 맥락이 모드 B로 자연스럽게 이어진다.
구현은 같은 messages 배열에 다 넣는 것이다.
'content': [
{'type': 'image_url',
'image_url': {'url': dataUrl}},
{'type': 'input_audio',
'input_audio': {'data': base64Audio, 'format': 'wav'}},
{'type': 'text',
'text': '아까 빨리 먹어야 한다고 했잖아요...'}
]
(lib/features/chat/data/repositories/chat_repository.dart)
비전+음성을 별도 모델로 분리한 구조라면 모달 간 컨텍스트 옮기는 코드를 한참 짜야 한다.
단일 옴니모달이라 통째로 사라진다.
모바일에서 카메라 → 마이크 전환이 빈번한 UX일수록 이 단순함이 핵심이 된다.
1-3. 한국어 STT 정확도: fine-grained NLP의 출발점
Kanana-o의 한국어 음성 인식 CER은 6.45다. (GPT-4o 23.19, Gemini 17.11)
받아쓰기가 정확해야 fine-grained 룰베이스 로직을 클라이언트에 짤 수 있다.
STT가 부정확하면 사용자가 어떤 단어를 말했는지조차 모르니까 클라이언트 NLP 자체가 안 된다.
이 정확도가 무엇을 가능하게 하는지는 2부에서 구체 사례로 보여준다.
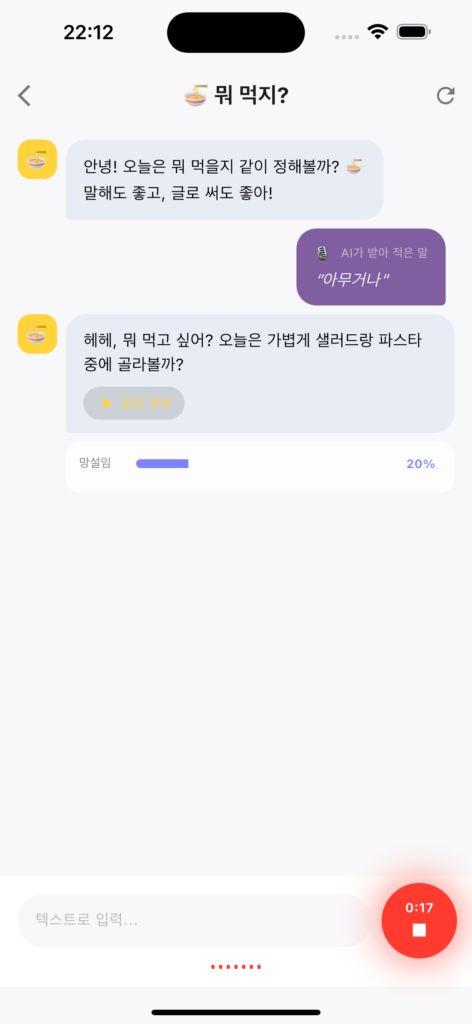
2부 — 비결정적 멀티모달 모델을 다루는 패턴
옴니모달은 강력하지만 비결정적이다. 같은 입력에 같은 출력이 보장되지 않는다.
클라이언트에서 이걸 다루지 못하면 UX가 깨진다.
한 달 동안 부딪힌 패턴들이다.
2-1. 음성 모달리티의 시스템 프롬프트 약화
디버그 로그를 보다가 발견했다. [DECISION], [USER_HEARD], [INTENT] 같은 메타 태그를 시스템 프롬프트에서 강하게 요구해도 음성 응답에서는 일관성이 떨어진다.
텍스트 호출에서는 잘 나오는데 음성에서만 빠진다.
가설은 음성 모달리티에서 시스템 프롬프트의 후반부 지시가 약하게 적용된다는 것이다.
대응: 매 음성 호출마다 짧은 텍스트 리마인더를 audio와 같은 user 메시지로 묶어 보낸다.
static const _voiceReminder = '''(시스템 리마인더 — 음성으로 읽지 마)
응답: 2-3문장, 친한 카톡 톤, 메뉴 최대 2개.
카테고리 나열 금지, 질문은 한 번에 하나만.''';
// 호출 시
'content': [
{'type': 'input_audio', 'input_audio': {...}},
{'type': 'text', 'text': _voiceReminder}, // 동봉
]
이 한 트릭으로 메타 태그 일관성이 눈에 띄게 올라갔다.
2-2. 한국어 confirm regex의 함정
리마인더로도 100% 일관성은 안 나온다.
그래서 클라이언트에 룰베이스 폴백을 만들었다.
사용자 발화에서 결정 확정 키워드를 매칭하는 단순한 패턴이다.
처음엔 짧았다.
final confirm = RegExp(r'(좋아|좋다|콜|오케이|그걸로|할게|가자|그래)');
디버그 로그에서 오탐이 줄줄이 보였다.
"그래"→"그래서","그래도"안에 그대로 잡힘"좋아?"(질문) → 확정으로 오인"안 좋아"(부정) → 확정으로 오인- 첫 턴
"좋아 빨리 정해줘"→ 추천도 안 했는데 결정 트리거
수정:
// 어미 anchoring + 모호한 표현 제거
final confirm = RegExp(
r'(좋아[!.]?$|좋다[!.]?$|콜|오케이|그걸로|할게|가자|이걸로|결정)',
);
// 부정/질문 명시 제외
if (RegExp(r'(안 좋|별로|좋아\?|싫)').hasMatch(user)) return null;
// 최소 2턴 조건 (첫 턴 false trigger 방지)
if (state.turnCount < 2) return null;
한국어는 어미와 문맥이 의미를 뒤집는 경우가 많다. 영어 NLP 패턴을 그대로 가져오면 다친다. 이 디버깅이 가능했던 출발점이 1-3절의 STT 정확도였다는 점을 다시 강조한다.

2-3. 단일 모달리티 폴백 호출
음성 호출이 USER_HEARD를 빠뜨리면 받아쓰기가 비고,
그러면 클라이언트 룰베이스 폴백도 무력해진다 (사용자 발화를 모르니까).
대응: USER_HEARD가 빠진 경우에만 단일 목적 폴백 호출을 보낸다. 받아쓰기 하나만 시킨다.
static const _transcribePrompt =
'''한국어 음성을 듣고 그대로 받아 적어. 다른 말 금지.
출력은 받아 적은 한국어 문장 한 줄만.''';
받아쓰기 한 가지만 시키면 모델이 다른 작업과 안 섞여서 형식 일관성이 훨씬 높다.
폴백 결과로 룰베이스 추출(INTENT/DECISION)을 재시도한다.
2-4. 수동 결정 버튼 — 사전 미커버 케이스
룰베이스 폴백의 한계는 메뉴 사전이다.
미리 짜둔 한국 메뉴 사전 40개(국밥, 김치찌개, 삼겹살 등)는 일반 한식엔 통하지만
메뉴판 OCR로 나오는 식당 고유 메뉴(예: 스파이시 토마토 파스타 + 미트볼)는 못 잡는다.
해결: 채팅 입력창 위에 “이걸로 결정!” 버튼을 둔다.
탭하면 AI 직전 응답에서 굵게 표시된 메뉴(**...**)를 자동으로 입력란에 채워주고
사용자가 확인/수정 후 확정한다.
자동(메타 태그) → 룰베이스 폴백 → 수동 버튼. 3중 안전망이다.
한 곳이 실패해도 다음 곳에서 잡힌다.

2-5. 인앱 디버그 로그 시스템
위 모든 디버깅이 가능했던 건 턴 단위 관찰성을 일찍 만들어둔 덕분이다. 매 턴 자동 기록되는 항목:
class DebugLogEntry {
final String sessionId;
final int turnIndex;
final ChatMode mode;
// 입력
final bool wasVoice;
final int? audioBytes;
final double? audioSeconds;
final String? userText;
final String? userTranscript;
// 모델 응답
final String rawResponse;
final String body;
final String? metaBlock;
// 파싱된 메타
final String? intent;
final EmotionData? emotion;
final String? decision;
final List<String> quickReplies;
// 진단 플래그
final bool metaSeparated; // 메타 분리 마커 정상 적용 여부
final bool metaFromFallback; // 폴백 호출로 메타가 채워졌는지
}
홈 우상단 디버그 아이콘으로 즉시 조회한다.
메타 태그 누락, regex 오탐, 폴백 호출 실패, 다 여기서 발견했다.
비결정적 멀티모달 모델을 다루려면 턴 단위 관찰성 인프라가 거의 필수다.
다른 LLM 통합 작업에도 그대로 적용 가능한 패턴이다.
모바일 연동 디테일 짧게
위 패턴들 외에 Flutter 모바일 연동 자체에서 부딪힌 디테일도 짧게 정리한다.
- SSE 스트리밍: Dart에 OpenAI SDK가 없어서 http 패키지로 SSE 파서를 100줄 안짝으로 자체 구현. OpenAI 호환 덕에 base_url + model 변경만으로 동작한다.
- 오디오 파이프라인: Kanana-o가 16kHz mono WAV를 요구한다. macOS에선 record 패키지의 sampleRate 옵션이 일부 무시돼 한참 헤맸고 결국 패키지가 직접 WAV 헤더를 쓰게 우회했다.
- 키 보안: OSS 공개를 위해 BYO-key 모델을 채택. 사용자가 본인 Kanana-o 키를 입력해야 동작하고 라우팅 가드가 키 미설정 시 설정 화면으로 강제 이동시킨다. 호출 비용 사용자 책임, 운영 비용 0.
마치며
Kanana-o의 진짜 가치는 “한국어 잘함”이 아니라, 한국 사용자가 한국어로 말할 때 발생하는 미묘한 것들을 모델이 알아서 처리해준다는 점이다. 그리고 옴니모달의 진짜 가치는 모달 간 컨텍스트 옮기는 코드가 통째로 사라진다는 점이다.
코드를 짧게 만드는 모델이 좋은 모델이다.
전체 코드는 GitHub에 공개해뒀다 → github.com/PlutoJoshua/amuguna
이 글은 카카오 AI 앰배서더 Kanana-o 베타 테스트 프로그램의 일환으로 작성됐다.
함께 읽으면 좋은 글
- KANANA 429: 카카오 AI 앰배서더 첫 밋업 후기
- Kanana in KakaoTalk을 켜봤다
- AI 개발자에게 멀티모달의 문턱을 낮춰주는 책 – “허깅페이스로 배우는 멀티모달 모델”
글쓴이 · Plutojoshua
핀테크에서 LLM과 AI 에이전트를 실제 서비스에 적용하는 개발자다. 카카오 AI 앰배서더로 Kanana 모델을 앱에 직접 연동해 검증하고, 비전공자로 시작해 실제 코드와 측정값을 근거로 “왜 그렇게 설계했는지”를 1인칭으로 기록한다. 운영자 소개는 About, 코드는 GitHub에서 볼 수 있다.
“Kanana-o 멀티모달을 Flutter 앱에 녹이며 – 강점 3가지와 비결정성을 다루는 패턴”에 대한 2개의 생각